3. De structurele dimensie van taal: Morfologie en Syntaxis
![]() e-mail
je reactie op dit college aan de docent <vderooij@pscw.uva.nl>
e-mail
je reactie op dit college aan de docent <vderooij@pscw.uva.nl>

![]() e-mail
je reactie op dit college aan de docent <vderooij@pscw.uva.nl>
e-mail
je reactie op dit college aan de docent <vderooij@pscw.uva.nl>
In dit college gaan we ons bezig houden met de lineaire en hierachische structuur van woorden, woordgroepen en zinnen. We zullen zien dat deze zijn opgebouwd uit kleinere elementen. We zullen ook zien dat we om bepaalde generalisaties te kunnen maken over observeerbare taalfeiten vaak een onderliggende structuur moeten aannemen (zie ook het voorgaande college) waaruit we met behulp van een of meer regels die observeerbare feiten (woorden, woordgroepen, zinnen) af kunnen leiden.
Wat we leren uit dit, het vorige, en het volgende college, die samen het eerste blok 'De structurele dimensie van taal' vormen is dat taal een systeem is dat bestaat uit een beperkte verzameling elementen die volgens bepaalde regels gerangschikt kunnen worden. De verschillende binnen een taal geoorloofde manieren waarop elementen gerangschikt worden tot grotere gehelen bepaalt hoe we die gehelen dienen te interpreteren. Om een heel simpel voorbeeld te geven: 'appelmoes' en 'moesappel' bestaan beide uit de woorden 'appel' en 'moes' maar betekenen niet hetzelfde. 'Appelmoes' is moes die gemaakt is van appels, terwijl 'moesappel' een appel(soort) is die zich bij uitstek leent voor het maken van apelmoes. Het is de verschillende volgorde waarin de elementen verschijnen die maakt dat we aan de nieuw gevormde eenheden verschillende betekenissen moeten hechten. Ook de manier waarop de volgorde van woordgroepen op het niveau van de zin wordt gevarieerd correspondeert met verschillende betekenissen die aan de verschillende structuren worden toegekend. Zo kunnen we de woordgroepen [de haveloze zwerver], [de dikke politie-agent] en [beet zonder enige aanleiding] op twee voor het Nederlands mogelijke manieren combineren:
(1a). [de dikke politie-agent][beet zonder enige aanleiding][de haveloze zwerver]
(1b). [de haveloze zwerver][beet zonder enige aanleiding][de dikke politie-agent]
Simpel gezegd komt het erop neer dat in het Nederlands de woordgroep die verwijst naar de handelende persoon altijd voorafgaat aan de woordgroep die verwijst naar de persoon (of voorwerp) die de handeling ondergaat.
De drie colleges in het deel 'De structurele dimensie van taal' zullen duidelijk maken wat de verschillende kernvragen zijn die de taalkundige bezighouden:
Een taalkundige probeert dus te ontdekken wat de emic eenheden zijn in een bepaalde taal. Dit gebeurt door middel van observatie maar vooral ook door middel van het werken met informanten. De taalkundige zal door het stellen van gerichte vragen over taalfeiten proberen te achterhalen wat de 'native' intuïties zijn om op die manier vast te stellen uit welke emic categorieën een taal bestaat, hoe zij een samenhangend systeem vormen, hoe zij gecombineerd kunnen worden om talige uitingen te vormen, en welke relaties er bestaat tussen de vorm en funtie van die uitingen.
Het zal duidelijk zijn dat de werkwijze van de antropoloog hiermee veel overeenkomsten vertoont. Ook de antropoloog begint met een zoektocht naar de basiseenheden, dit keer van cultuur en sociale structuur. Ook bij de antropoloog spelen observatie en interactie met 'native' informanten met als doel te komen tot een dieper inzicht van de 'native point of view', een essentiële rol. Ook de antropoloog probeert te achterhalen wat de structurele samenhang is tussen cultuur-elementen, en op welke wijze ze gecombineerd kunnen worden tot betekenisvolle uitingen.
Er zijn natuurlijk ook belangrijke verschillen tussen taalkunde en antropologie. Vooral de afgelopen decennia heeft de taalkunde zich steeds meer ontwikkeld tot een wetenschap die probeert taalfeiten uit verschillende talen te beschrijven en te verklaren met behulp van vooronderstelde universele principes. Binnen de antropologie is, zeker na de 'val' van het Lévi-Straussiaanse structuralisme, weinig plaats voor een dergelijke universalistische benadering. Toch zullen antropologen altijd geconfronteerd worden met de vraag wat de emic categorieën zijn van de cultuur/samneleving waarin ze onderzoek doen. Daarbij zullen altijd, net als in de taalkunde, observatie, formalisering en categorisering van waarnemingen een kernactiviteit blijven. Ook zal, net als in de taalkunde, bij het analyseren (lees: interpreteren) van onderzoeksgegevens, vaak, zo niet altijd, een beroep moeten worden gedaan op onderliggende structuren die met behulp van regels of procedures getransformeerd worden in waarneembare uitingen.
Morfologie is de studie van gelede woorden. Gelede woorden zijn woorden die samengesteld zijn uit twee of meer morfemen. Een morfeem is het kleinste element in een taal dat een betekenis draagt of een grammaticale functie heeft. Zo is het Nederlandse woord #boeken# (# is het symbool voor woordgrens) opgebouwd uit twee morfemen: 'boek' en 'en'. 'Boek' is een betekenisdragend morfeem en 'en' is een morfeem met een grammaticale functie: het drukt namelijk meervoud uit. Zo'n geleed woord wordt vaak als volgt weergegeven: #boek+en#, waarbij + staat voor morfeemgrens. Het tweelettergrepige woord #morgen# bestaat uit slechts één morfeem. Je kunt dit woord wel verder opdelen in lettergrepen ('mor' en 'gen') maar die hebben ieder afzonderlijk geen betekenis of functie in het Nederlands.
Talen verschillen erg in de mate waarin ze gebruikmaken van gelede woorden. Sommige talen, zoals het Chinees of Vietnamees (cf. Finegan 1999:54), kennen naast compounds of samenstellingen, woorden die zijn samengesteld uit twee of meer woorden zoals 'taalwetenschap', en geredupliceerde woorden eigenlijk geen gelede woorden. Dit geldt ook voor veel creooltalen, zoals het Saramaccaans dat gesproken wordt door een van Suriname's Bosnegervolken. Je ziet dit duidelijk in (2) waar een bijna perfecte één op één relatie bestaat tussen woorden en morfemen (alleen van 'a' zou je kunnen zeggen dat het meer dan een betekenis in zich verenigt: 3de persoon + enkelvoud, maar ik weet van geen taal waarin deze combinatie van betekenissen door twee afzonderlijke morfemen uitgedrukt wordt). Alle morfemen vormen dus zelfstandige 'losstaande' betekeniseenheden. Daarom noemt men deze talen vaak isolerende of analytische talen.
| (2). Saramaccaans | ||||||
| A | k�nda | w�ta | t�e | a | d� | f�ja. |
| 3 SG | tilt | water | throw | LOC | DET | fire |
|
'He poured water onto the fire' (Veenstra 1996:168) |
||||||
|
3 SG staat voor 3de persoon singularis of enkelvoud LOC staat voor locatief, in dit geval een prepositie of voorzetsel DET staat voor determiner, in dit geval een lidwoord |
||||||
Naast isolerende bestaan er ook talen waarin meerdere morfemen die elk een afzonderlijke lexicale of grammaticale betekenis uitdrukken aan elkaar vastgeplakt kunnen worden om langere woorden te vormen. Deze talen worden agglutinerend genoemd. Bekende voorbeelden zijn het Turks en Hongaars. In (3) zie je een Turks woord. Om dit ene Turkse woord in het Nederlands te vertalen heb je drie woorden nodig. In het Turks 'plak' je namelijk aan het zelfstandige naamwoord (hier is dat 'ev-') allerlei morfemen vast die lexicale en grammaticale betekenis uitdrukken, waar wij in het Nederlands aparte woorden gebruiken.
| (3).Turks | ||||||
| ev- | çik- | ler- | imiz- | de | ||
| huis | klein | MV | ons | in/op | ||
| 'in onze huisjes' (Appel et al. (1992:86) |
||||||
| MV staat voor meervoud | ||||||
Ook zijn er talen waarin het mogelijk is om bijvoorbeeld zelfstandige naamwoorden 'in te sluiten' in een werkwoord (we noemen dit incorporatie) waardoor een qua structuur en betekenis complex woord ontstaat dat vaak tegelijkertijd woord en zin is. In (4) zie je hier een voorbeeld van. In dit woord (of woordzin) uit het Fox, een Noordamerikaanse Indiannetaal, zie je dat een bijwoord ('eh-') en een zelfstandig naamwoord ('-kiwin-') aan het werkwoord ('-a-') vastgeplakt zijn. Talen waarin incorporatie een prominente rol speelt worden polysynthetisch genoemd.
| (4). Fox | |||||||
| eh- | kiwin- | a- | m- | oht- | ati- | wa- | ch(i) |
| dan | beweging | vluchten | CAUS | zich | elkaar | MV | 3PS |
|
'Toen joegen ze het met elkaar op de vlucht (voor hen)' (Appel et al. 1992:87) |
|||||||
|
CAUS staat voor causatief; het causatief morfeem verandert de betekenis van het werkwoord 'vluchten' in 'doen vluchten, op de vlucht jagen' MV staat voor meervoud 3PS staat voor 3de persoon |
|||||||
Tenslotte wordt er nog een type talen onderscheiden waarin wel zoals in agglutinerende talen complexe woorden gevormd kunnen worden die bestaan uit meerdere morfemen, maar in die morfemen zijn vaak meerdere betekenissen of grammaticale functies met elkaar versmolten of gefuseerd (Spencer 1991:38). Een voorbeeld hiervan vind je in (5), waar de uitgang '-o' van het werkwoord drie betekenis- of functie-elementen in zich verenigt: 1ste persoon, singularis (enkelvoud), presens (tegenwoordige tijd). Alle talen met een uitgebreid systeem van naamvallen of werkwoordsvervoegingen (Russisch, Duits, Latijn, Arabisch) zijn prototypische voorbeelden van deze categorie talen die traditioneel als flecterende (in het Engels (in)flectional) talen worden aangeduid. Vanwege de fusie van betekeniselementen in één morfeem die in deze talen vaak voorkomt, wordt ook wel gesproken van fuserende talen.
| (5). Latijn | |
| clam- | o |
| roepen | 1.SG.PRS |
| ik roep | |
Deze traditionele indeling van talen op basis van hoe morfemen wel of niet gecombineerd worden is zoals Spencer (ibid.) opmerkt niet erg coherent. Veel polysynthetische talen zou je ook prima kunnen classificeren als agglutinerende talen met de mogelijkheid van incorporatie. Bovendien is deze indeling in de praktijk niet goed bruikbaar als je afzonderlijke talen probeert onder te brengen in één categorie. Het Engels bijvoorbeeld combineert een isolerende tendens met een zekere mate van agglutinatie en kent daarbij zelfs een beetje incorporatie dat typisch is voor polysynthetische talen (Spencer: ibid.). Het Quechua, een Zuidamerikaanse indianentaal, wordt algemeen beschouwd als een typische agglutinerende taal maar zelfs in een taal als het Quechua vinden we hier en daar tekenen van fusie, een typische eigenschap van flecterende talen. Dat is te zien in (6) waar '-rqa' drie betekeniselementen in zich verenigt: 3de persoon, enkelvoud, en verleden tijd. Ik heb hier de termen isolerend, agglutinerend, polysynthetisch, en flecterend eigenlijk alleen maar geïntroduceerd om te illustreren hoe verschillend talen morfemen combineren (of juist niet). Het is daarom beter niet te spreken van isolerende, agglutinerende, etc. talen, maar van talen met een sterker of zwakker isolerend, agglutinerend, etc. karakter.
| (6). Quechua | ||||||
| mama- | y | kacha- | rpaya- | kipa- | wa- | rqa |
| mother | 1SG | send | INT | REP | 1OB | 3SGPST |
|
'Again and again my mother said good-bye to me.' (van de Kerke 1996:69) |
||||||
|
1SG staat voor 1ste persoon singularis of enkelvoud INT staat voor intentioneel (aspect van het werkwoord) REP staat voor repetitief (aspect van het werkwoord) 1OB staat voor object(markeerder), 1ste persoon 3SGPST staat voor derde persoon enkelvoud, verleden tijd |
||||||
Kijkend naar de voorbeeldzinnen hierboven, kun je constateren dat er twee soorten morfemen zijn. Er zijn aan de ene kant morfemen die nooit zelfstandig, dat wil zeggen als afzonderlijk woord, voor kunnen komen. Een voorbeeld is het Turkse ler uit (2) of het Nederlandse s in appel+s. Beide morfemen veranderen het getal van het zelfstandig naamwoord waaraan ze vastzitten van enkelvoud in meervoud en hebben als zodanig een grammaticale functie. Als geïsoleerd morfeem, dus zonder een voorafgaand zelfstandig naamwoord, drukken ler en s echter niets zinnigs uit. We noemen dit soort morfemen gebonden of, in het Engels, bound morfemen. De tegenhangers van gebonden morfemen zijn vrije of free morfemen, die juist wel als zelfstandig woord voor kunnen komen. Voorbeelden in het Nederlands zijn het zelfstandig naamwoord 'jongen', en het bijvoeglijk naamwoord 'lang'. In (7) zijn de vrije en gebonden morfemen in een Nederlandse zin weergegeven.
| (7). Vrije en gebonden morfemen in een Nederlandse zin | |||||||||||||
| In | zijn | vroeg | +e | werk | schilder | +de | hij | met | bruin | +achtig | +e | kleur | |
| VRIJ | VRIJ | VRIJ | GEB | VRIJ | VRIJ | GEB | VRIJ | VRIJ | VRIJ | GEB | GEB | VRIJ | |
Deze sectie is voor het grootste deel een parafrase van Appel et al. (1992:93-94) en gaat in op het problematische karakter van het concept 'morfeem'. Een geleed woord als 'schurkachtigheid' laat zich probleemloos als volgt in afzonderlijke morfemen opdelen: #schurk+achtig+heid#. Anders is dit met een woord als 'loop' in de zin 'Ik loop'. Deze ene vorm 'loop' bevat de volgende betekeniselementen: 1ste persoon, enkelvoud (of singularis), tegenwoordige tijd (of presens), en de handeling 'lopen'. Toch laat 'loop' zich niet verder opdelen in kleinere vormelementen die corresponderen met deze betekeniselementen. Naast dit soort woorden waarin één vorm meerdere betekeniselementen in zich verenigt, zijn er woorden die bestaan uit meerdere vormelementen die samen slechts één betekenis uitdrukken. 'Bericht' is zo'n woord. Het bestaat uit twee delen: 'be+' dat we in ook in andere woorden ('be+reik', 'be+sluit', enzovoorts) tegenkomen en 'richt'. De betekenis van 'bericht' echter laat zich niet afleiden uit de optelsom van beide delen: er is sprake van twee vormelementen die samen één betekenis uitdrukken. In deze, en vele andere, gevallen is er dus geen sprake is van een directe één op één relatie tussen vorm- en betekeniselement. Toch wordt het begrip 'morfeem' nog steeds gebruikt omdat het erg handig is gebleken in het beschrijven van vele talen en verder omdat het simpelweg zo is ingeburgerd in de taalkunde dat het niet meer weg te denken is.
Als we kijken naar de Nederlandse verkleinwoorden in (8) dan lijken er in het Nederlands op het eerste gezicht verschillende 'verklein'morfemen te zijn.
(8a). appel+tje
(8b). muis+je
(8c). man+etje (in normale spelling: 'mannetje)
(8d). woning+kje
(8e). naam+pje
Als we beter gaan kijken, dan zullen we tot de conclusie komen dat we in feite met slechts één morfeem te maken hebben dat in verschillende fonologische contexten op verschillende manieren wordt gerealiseerd. We noemen zulke fonologisch geconditioneerde verschijningsvormen van een morfeem allomorfen. Het is misschien leuk om zelf uit te zoeken met welke regels je de taalfeiten in (8) kunt beschrijven. Afhankelijk van de uitkomst van je analyse kun je dan vaststellen welke vorm beschouwd moet worden als het onderliggende morfeem. Allomorfische variatie is meestal, zoals ook in dit geval, niet afdoende te beschrijven met regels die allen fonologische informatie bevatten. Zo moet in de regel (of regels) die bepaalt welke vorm het verkleinmorfeem krijgt, gespecificeerd worden dat hij alleen werkt in een bepaalde morfologische omgeving. We spreken daarom in gevallen als deze over morfo(fo)nologische regels
As we gaan kijken naar de morfemen die in het Nederlands een meervoud maken van een enkelvoudig zelfstandig naamwoord (we laten nu even andere meervoudsvormen bij woorden die ontleend zijn uit andere talen zoals 'museum/musea', 'stigma/stigmata', 'crisis/crises' buiten beschouwing), dan zien we de volgende vormen:
(9a). appel+s
(9b). vrouw+en
We zouden nu natuurlijk '+s' en '+en' ook als allomorfen kunnen beschouwen. Aan de ene kant ligt dit voor de hand omdat zij dezelfde functie vervullen (het markeren van de grammaticale categorie 'meervoud') maar anders dan in het geval van de 'verklein'allomorfen kunnen we hier met geen mogelijkheid de verschillende vormen als fonologisch geconditioneerde varianten van een onderliggend morfeem bestaande uit een reeks fonemen afleiden. In dit soort gevallen, aldus Spencer (1991:41), is het beter niet over een morfeem en zijn allomorfen, maar over een grammaticale categorie (in dit geval 'MEERVOUD') en zijn exponenten (in dit geval '+s' en '+en') te spreken. Je ziet, ook hier is het klassieke morfeem-concept, met de aanname dat er een één op één relatie tussen vorm-betekenis/functie moet zijn, slecht toepasbaar.
Affixatie (eigenlijk een anglicisme voor affigering) is het proces van woordvorming waarbij aan of in het woord morfemen toegevoegd worden die we affixen noemen. Affixen zijn altijd gebonden morfemen en zijn er in verschillende typen. We onderscheiden prefixen die voor een woord geplaatst worden (on+waar) en suffixen die achter het woord geplaatst worden (waar+heid) komen in vele talen voor. Zeldzamer zijn infixen die in een woord geplaatst worden. Appel et al. (1992:90) geven een voorbeeld uit het Bontoc, een taal die op de Filippijnen wordt gesproken, waar het infix '+um+' voorkomt dat van een woord als 'kilad' (rood) k+um+ilas (hij wordt rood) maakt.
Soms wordt nog een derde vorm van affixen onderscheiden, circumfix of dicontinu affix genoemd. In Nederlandse voltooide deelwoorden zouden we 'ge+[werkwoordstam]+{d,t}' als een circumfix kunnen beschouwen: ge+kam+d, ge+kap+t. Volgens vele taalkundigen moeten alle vormen van circumfigering echter beschouwd worden als een combinatie van pre- en suffigering (Spencer 1991:13).
Sommige taalkundigen werken ook met zogenaamde nul-affixen (in het Engels null of zero affixen genoemd), bijvoorbeeld om het verschijnsel te beschrijven waarbij dezelfde vorm kan functioneren als twee woorden die tot verschillende categorieën behoren. Een voorbeeld uit het Engels is 'hand'. Deze vorm kan een zelfstandig naamwoord zijn maar ook een werkwoord: '(to) hand'. Vaak wordt dit verschijnsel conversie of multifunctionaliteit (Appel et a. 1992:89-90; Spencer 1991:21) genoemd en wordt aangenomen dat een vorm als 'hand' gewoon van woordcategorie kan wisselen. Je kunt echter ook stellen dat de verandering van zelfstandig naamwoord in werkwoord tot stand wordt gebracht door affigering van een nul-affix. Onderliggend is er dan een affix aanwezig maar dit affix wordt niet fonologisch gerealiseerd: het is fonologisch leeg.
Traditioneel worden twee verschillende processen van affigering onderscheiden: flexie (buiging) en derivatie (afleiding). Over flexie spreken we wanneer een affix aan een woord wordt vastgeplakt zonder dat dat woord van categorie verandert. In het Nederlands komen we flexie bijvoorbeeld tegen in de vervoeging van het werkwoord. In Tabel 4.1 is de vervoeging van het werkwoord 'lopen' in de tegenwoordie tijd gegeven.
| Singularis (Enkelvoud) | |
| (ik) wens | (+ø) |
| (jij) wens | +t |
| (z/hij) wens | |
| Pluralis (Meervoud) | |
| (wij) wens | +en |
| (jullie) wens | |
| (zij) wens | |
Als je aanneemt dat de vorm '(ik) loop' een nul-suffix heeft (aangeduid met ø) dan zien we in de tabel drie flexie-affixen: +ø voor de eerste persoon enkelvoud, +t voor de tweede en derde persoon enkelvoud, en +en voor eerste, tweede en derde persoon meervoud. De woorden 'wens+ø', 'wens+t', en 'wens+en' die ontstaan als gevolg van flexie zijn alle nog steeds werkwoorden: er heeft dus geen verandering van woordcategorie plaatsgevonden ten opzichte van de stam 'wens'. Inflectie wordt in de talen van de wereld veel gebruikt om tijd, persoon, getal (enkel/meervoud), en naamval te markeren.
Derivatie is het proces van affigering waardoor een nieuw woord gevormd wordt. Dit in tegenstelling tot flexie waar de vormen die ontstaan door affigering varianten zijn van hetzelfde woord of, beter gezegd, van hetzelfde lexicale item in het mentale lexicon: de woordvormen 'wens+ø', 'wens+t', en 'wens+en' worden niet als afzonderlijke items in het mentale lexicon opgenomen. Dit is vaak wel het geval bij woorden die ontstaan door derivatie: 'jacht' en 'jachtig' uit (10) zitten als aparte lexicale items in ons mentale lexicon. Meestal (maar niet altijd) gaat derivatie ook gepaard met verandering van woordcategorie. Hier zijn een aantal voorbeelden uit het Nederlands:
(10a). jacht+ig
(zelfstandig naamwoord -> bijvoeglijk naamwoord)
(10b). jachtig+heid (bijvoeglijk naamwoord -> zelfstandig naamwoord)
(11). afleidingen
vanuit de werkwoordstam schrijv-
(11a). schrijv+er (werkwoord -> zelfstandig naamwoord)
(11b). schrijver(s)+achtig (zelfstandig naamwoord -> bijvoeglijk
naamwoord)
(11c). schrijver(s)achtig+heid (bijvoeglijk naamwoord -> zelfstandig
naamwoord)
In (10) zien we een verschijnsel optreden dat vaak voorkomt bij derivatie. In de betekenis van het afgeleide woord 'jachtig' vinden we niet meer duidelijk de oorspronkelijke betekenis van het woord 'jacht' terug. 'Jachtig' betekent niet (langer) 'te maken hebbend met de jacht (de activiteit van een dier zoeken of nazitten om het te doden met een wapen)', maar heeft een meer abstractere betekenis gekregen. Dit soort betekenisverschuiving en -specialisatie is typerend voor derivatie en komt practisch niet voor bij flexie (Appel et al. 1992:97).
Ik wil deze sectie niet besluiten zonder te vermelden dat het onderscheid tussen flexie en derivatie niet altijd even makkelijk is te maken. Dat is voor een aantal linguïsten ook reden om geen principieel onderscheid tussen deze twee processen te maken (zie Spencer 1991:193 voor een bespreking van dit probleem).
Een van de meest gebruikte manieren om nieuwe woorden te maken is het simpelweg samenvoegen van woorden. We noemen dit soort woorden compounds of samenstellingen (of met een mooi Latijs woord composita, compositum in het enkelvoud). In het Nederlands vinden we samenstellingen die bestaan uit verschillende combinaties van woordcategorieín:
(12a). raam-opening
(zelfstandig naamwoord-zelfstandig naamwoord)
(12b). zwart-boek (bijvoeglijk naamwoord-zelfstandig naamwoord)
(12c). donker-bruin (bijvoeglijk naamwoord-bijvoeglijk naamwoord)
(12d). schrijf-practicum (werkwoord-zelfstandig naamwoord)
Blends, de naam zegt het al, zijn woorden waarin twee woorden met elkaar vermengd of verstrengeld zijn. We kennen dit verschijnsel vooral uit het Amerikaans Engels. Denk aan 'motel' (motor car + hotel), 'brunch' (breakfast + lunch), 'infotainment' (information + entertainment), 'edutainment' (education +entertainment). Bestaande woorden kunnen ook een nieuwe vorm krijgen door een afkorting van het woord te gebruiken of door een deel of delen ervan weg te laten: tv/teevee (televisie), pomo (postmodern). Tenslotte is het nog mogelijk een samenstelling te maken van twee ingekorte woorden. Een bekend voorbeeld is 'biopic' (biography + picture)
Het in zijn geheel of gedeeltelijk herhalen van morfemen of woorden wordt in zeer veel talen gebruikt als woordvormingsproces. We noemen dit reduplicatie. Reduplicatie dient vaak om de betekenis van het geredupliceerde woord te versterken of te verzachten (Finegan 1999:49).
In talen met flecterende tendens kom je vaak het verschijnsel ablaut tegen, waarbij de klinker van een stam verandert. In het Nederlands zien we dit in de verleden tijdsvormen van sterke werkwoorden: eet versus at. In het Duits zien we ook vaak ablaut optreden in meervoudsvorming.
Backformation is een proces waarbij een woord geherinterpreteerd wordt en op basis van die herinterpretatie een nieuw woord gevormd wordt. Zo was het Nederlandse woord 'schoen' ooit een meervoudsvorm van 'schoe', maar door het woord te herinterpreteren als enkelvoud is de nieuwe meervoudsvorm 'schoen+en' ontstaan.
Tot nu toe hebben we ons beziggehouden met de kleinste bouwstenen van een taal: fonemen en morfemen. We gaan nu kijken naar grotere taaleenheden: zinnen. De lineaire structuur of woordvolgorde en de hierarchische structuur van zinnen vormen het onderzoeksterrein van de syntaxis. Iedere normale bevestigende zin bestaat uit twee delen: een referentiële uitdrukking (referring expression) die verwijst naar een bepaalde persoon of zaak die we een entiteit (entity) noemen en een predicerende uitdrukking (predication) die bepaalde eigenschappen toekent aan een entiteit (Appel et al. 1992:101; Finegan 1999:142). In (13a) is 'hij' de referentiële uitdrukking en 'slaapt' is de predicerende uitdrukking. Referentiële en predicerende uitdrukkingen zijn de hoofdbouwstenen van de zin. Dit wordt duidelijk als we kijken naar de zinnen (13b-c).
(13a). [Hij] [slaapt]
(13b). [De man] [slaapt]
(13c). [De dikke man] [slaapt]
Je ziet dat 'hij', de referentiële uitdrukking in (13a), vervangen kan worden door twee woorden 'de man'. Die twee woorden 'gedragen' zich als een eenheid. We kunnen ze niet omwisselen of één van beide op een andere plaats in de zin zetten. 'De man' op zijn beurt kunnen we weer vervangen door 'de dikke man' als in (13c). Ook 'de dikke man' gedraagt zich weer als een eenheid. We zien dit aan de volgende ongrammaticale zinnen (14a-d) waarin de volgorde van de woorden 'de dikke man' is veranderd of waarin één van de woorden is verplaatst naar de laatste positie van de zin als in (15a-c) (*geeft aan dat de eropvolgende zin ongrammaticaal is):
*(14a). De man
dikke slaapt
*(14b). Dikke man de slaapt
*(14c). Man de dikke slaapt
*(14d). Man dikke de slaapt
*(15a). De man
slaapt dikke
*(15b). De dikke slaapt man
*(15c). Dikke man slaapt de
Dat 'de dikke man' als eenheid waarvan de lineaire volgorde vastligt fungeert, wordt ook duidelijk aangetoond wanneer we (13c) vragend maken:
(16) Slaapt [de dikke man]?
Hier zie je dat, ook al is de woordvolgorde van de zin veranderd, 'de dikke man' toch bij elkaar blijft. Het is duidelijk dat 'de dikke man' een syntactische eenheid is. We noemen zo'n eenheid een constituent. In dit geval gaat het om een nominale consituent (noun phrase) met als kern een zelfstandig naamwoord (noun). Referentiële uitdrukkingen bestaan altijd uit een noun phrase of, afgekort, een NP. Maar NP's kunnen ook deelconstituenten zijn van predicerende uitdrukkingen.
De predicerende uitdrukking van een zin wordt beschouwd als één constituent, VP genoemd, wat een afkorting is voor verb phrase (verbale constituent). Samen met een NP die als referentiële uitdrukking fungert vormt een VP een zin, vaak afgekort tot S (van 'sentence') in de formele notatie van zinsstructuren. Ik zal hier in notaties van zinsstructuren S alleen noteren als dat van belang is voor wat ik duidelijk wil maken. NP's of VP's kunnen bestaan uit één woord: zo is in (13a) 'slaapt' een VP en het persoonlijk voornaamwoord 'hij' een NP. Eénwoord NP's kunnen ook bestaan uit een eigen naam of een 'kaal' zelfstandig naamwoord zoals geïllustreerd in (17) waar het kale zelfstandige naamwoord 'boter' deel is van een VP.
(17). [S [NP Jan] [VP haat [NP boter]]]
Meestal echter is de structuur van NP's en VP's een stuk uitgebreider. We hebben al gezien in (13a-c) dat een NP 'uitbreidbaar' is. We kunnen (13c) zelfs weer verder uitbreiden als in (18a) met een deelconstituent die bestaat uit het voorzetsel of prepositie (preposition) 'met' gevolgd door de NP 'een drankneus'. We noemen zo'n constituent een prepositionele of voorzetsel constituent (prepositional phrase). In (18b) gaan we weer een stapje verder met de toevoeging van een betrekkelijke bijzin, in (18c) wordt de NP 'mijn raam' in die bijzin weer uitgebreid met de PP 'op de tweede verdieping'. In (18d) tenslotte wordt de NP 'de eerste verdieping' uitgebreid met de PP 'van het Spinhuis'. De haakjesnotatie die hier gebruikt wordt om de constituenten en hun onderlinge relaties weer te geven wordt labeled bracketting genoemd omdat rechts van het haakje dat het begin van een constituent aangeeft de naam of label van dat constituent in subscript gegeven wordt. Het nadeel van labeled bracketting is dat bij ingewikkelder structuren zoals in (18b-d) het overzicht zoek raakt. Daarom heb ik hier het label van de constituent herhaald links voor het haakje dat die constituent afsluit.
| (18a). | [NP De dikke man [PP met [NP een drankneus NP] PP] NP] [slaapt] |
| (18b). |
[NP De dikke man [PP met [NP
een drankneus NP] PP] [S die [NP ik NP] [VP zie [PP vanuit [NP mijn raam NP] PP] VP] S] NP] [slaapt] |
| (18c). |
[NP De dikke man [PP met [NP
een drankneus NP] PP] [S die [NP ik NP] [VP zie [PP vanuit [NP mijn raam [PP op [NP de tweede verdieping NP] PP] NP] PP] VP] S] NP] [slaapt] |
| (18d). | [NP De dikke man [PP met [NP een drankneus NP] PP] [S die [NP ik NP] [VP zie [PP vanuit [NP mijn raam [PP op [NP de tweede verdieping [PP van [NP het Spinhuis NP] PP] NP] PP] NP] PP] VP] S] NP] [slaapt] |
In principe kunnen we NP's (en PP's) op deze manier blijven uitbreiden omdat een PP als deel van een NP op zijn beurt weer een NP bevat die weer een PP kan bevatten enzovoorts. We noemen dit verschijnsel recursiviteit: binnen een NP of PP kan op een lager niveau diezelfde constituent opnieuw ingebed worden. In theorie kan dit eindeloos doorgaan maar in de praktijk zijn constituenten met meer dan twee of drie inbeddingen zeldzaam omdat deze ingewikkelde structuren al snel te veel moeite kosten om de interpreteren. Ook de structuur van VP's is recursief uitbreidbaar. We zien dat in de volgende zinnen.
| (19a). |
[Hij] [VP rent] |
| (19b). |
[Hij] [VP rent [PP door [NP de sneeuw NP] PP] VP] |
| (19c). |
[Hij] [VP rent [PP
door [NP de sneeuw [S
die [VP [PP
in [NP dikke vlokken NP] PP] neervaltVP] S] NP] PP] VP] |
| (19d). |
[Hij] [VP rent [PP
door [NP de sneeuw [S die [VP [PP
in [NP dikke vlokken NP] PP] neervalt [PP
op [NP het erf NP] PP] VP] S] NP] PP] VP] |
| (19e). |
[Hij] [VP rent [PP
door [NP de sneeuw [S die [VP [PP
in [NP dikke vlokken NP] PP] neervalt [PP op [NP het erf [PP van [NP het huis NP] PP] NP] PP] VP] S] NP] PP] VP] |
| (19f). |
[Hij] [VP rent [PP
door [NP de sneeuw [S die [VP [PP
in [NP dikke vlokken NP] PP] neervalt [PP op [NP het erf [PP van [NP het huis [PP langs [NP de weg NP] PP] NP] PP] NP] PP] VP] S] NP] PP] VP] |
| (19f). |
[Hij] [VP rent [PP
door [NP de sneeuw [S die [VP [PP
in [NP dikke vlokken NP] PP] neervalt [PP op [NP het erf [PP van [NP het huis [PP langs [NP de weg [PP naar [NP het meer NP] PP]NP] PP] NP] PP] NP] PP] VP] S] NP] PP] VP] |
In (19b) wordt de VP uitgebreid met een PP ('door de sneeuw'). In (19c) wordt de NP ('de sneeuw') in deze PP uitgebreid met een relatieve bijzin en in (19d) wordt de VP ('in dikke vlokken neervalt') uit deze bijzin uitgebreid met een PP ('op het erf'). In de zinnen (19e-f) wordt telkens een NP uitgebreid met een PP.
De structuur van constituenten kan worden beschreven met herschrijfregels (phrase structure rules). Enigszins vereenvoudigde, niet-uitputtende, herschrijfregels voor Nederlandse VP's, NP's en PP's AP's (Adjectival Phrases/adjectivale constituenten) zien er uit als in (20a-d).
| (20a). | VP -> | (NP) | (NP) | V | ||
| ..dat hij.. | het kind | een verhaal | vertelde | |||
| ..dat hij.. | een verhaal | schreef | ||||
| ..dat hij.. | huilde | |||||
| (20b). | NP -> | (DET) | (A) | N | (PP) | (S) |
| de | oude | mannen | met baarden | die rondslenteren | ||
| (20c). | PP -> | (Bijwoord) | P | (NP) | ||
| onmiddellijk | na | het stoplicht | ||||
| ..hij ligt.. | ver | achter | ||||
| (20d). | AP -> | (Bijwoord) | A | (PP) | ||
| ..hij is.. | helemaal | gek | van voetbal |
Op het waarom van de woordvolgorde in de zinnen in (20a) zal ik verderop nog terugkomen. Kijkend naar de herschrijfregels in (20) zie je dat alle constituenten een verplicht kernelement hebben: V in VP, N in de NP, en P in PP. Dit noemen we de lexicale hoofden (lexical heads) van constituenten. In modernere opvattingen van constituentstructuur en herschrijfregels binnen de Chomskyaanse traditie gaat men ervan uit dat VP, NP, AP, PP alle dezelfde hierarchische, structuur hebben bestaande uit drie nivo's. In (21) is die structuur in de vorm van een boomdiagram weergegeven.
(21). De gelaagde structuur van constituenten
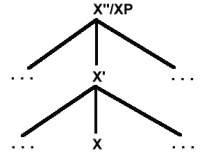
In dit schema kan X staan voor V (Verb), N (Noun), A (Adjective), en P (Preposition). X'' (meestal als aangeduid met XP) en X' noemen we projecties van X, het lexicale hoofd van de constituent. X wordt wel de zero projection genoemd en aangeduid met X0. X'' is de maximal projection (maximale projectie) en X' (dat recursief kan optreden) de intermediate projection. X' noemen we X-bar en X'' X-double bar. Deze opvatting van constituentstructuur staat bekend als X-bar theory (voor een heldere inleiding, zie Haegeman 1991:78-96). Bij (21) horen de volgende herschrijfregels:
| (22a). | X''/XP | -> | Spec; X' |
| (22b). | X'* | -> | X'; YP |
| (22c). | X' | -> | X; YP |
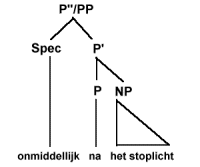
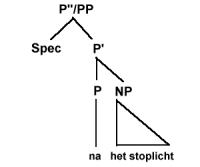
De posities direct onder de hoogste knoop X''/XP in (21) die aangegeven worden met puntjes, geven aan dat op één van die plaatsen een zogenaamde specifier (afgekort Spec) kan staan, zoals ook uitgedrukt in (22a). In (22c) wordt uitgedrukt dat X zich met een complement YP kan verbinden tot X'. (22b) drukt uit dat X' zich kan verbinden met een adjunctie (adjunct), een optionele XP, tot een nieuwe tussenliggende projectie (intermediate projection) X' van het lexicale hoofd X. Het symbool * geeft aan dat er hier sprake kan zijn van recursiviteit (je kunt dus in principe een oneindige reeks van tussenliggende projecties X' krijgen). De punt-komma (;) in (22a-c) geeft aan dat de volgorde van de lementen links en rechts ervan niet gespecificeerd is. Die volgorde is taalspecifiek en niet universeel. Aan de hand van het schema in (21) en de regels in (22) kunnen we de structuur van VP's, NP's, AP's en PP's in boomdiagrammen weergeven. Hier zijn een paar voorbeelden van PP's.
| (23a). | (23b). | (23c). |
 |
 |
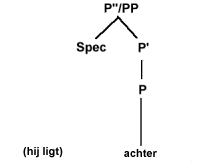 |
In (23a) zien we een compleet 'ingevulde' structuur met een specifier (het adverbium of bijwoord 'onmiddelijk') een prepositie ('na') en een NP ('het stoplicht'). In (23b) is de specifierpositie niet gevuld, terwijl in (23c) alleen het lexicale hoofd ('achter') aanwezig is.
Een typerend kenmerk van bijna alle stromingen binnen de moderne theoretische taalkunde is het uitgangspunt dat concrete taaluitingen afgeleid zijn van onderliggende structuren. We hebben dit al eerder gezien in de fonologie en morfologie, waar onderliggende fonemen en morfemen op verschillende manieren gerealiseerd kunnen worden in de vorm van respectievelijk allofonen en allomorfen. Ook in de syntaxis wordt algemeen aangenomen dat concrete taaluitingen de veruitwendiging zijn van onderliggende structuren die bepaalde bewerkingen kunnen ondergaan. De meeste taalkundigen die werken binnen de Chomskyaanse traditie nemen vier nivo's aan:
In schematische vorm ziet dit model er als volgt uit:
(24).
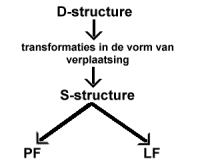
Het werken met onderliggende structuren die transformaties in de vorm van verplaatsingen kunnen ondergaan komt vooral voort uit het verlangen om variatie die we tegenkomen in concrete taaluitingen te beschrijven en te verklaren. Welke voordelen een syntactische theorie biedt die werkt met onderliggende structuren kan duidelijk worden gemaakt aan de hand van een bespreking van de woordvolgorde in het Nederlands (voor wat volgt heb ik me met name laten leiden door Haegeman's (1991:522-531) bespreking van het zogenaamde verb-second verschijnsel).
Als we naar een Nederlandse zin als in (25a) kijken, zouden we daaruit kunnen concluderen dat de Nederlandse woordvolgorde Subject (Onderwerp) - (geflecteerd) Werkwoord - Object (lijdend voorwerp) is, kortweg SVO (Subject - Verb - Object). Kijken we verder naar andere Nederlandse zinnen als (25b-d) dan zien we echter ook andere woordvolgordes.
(25a). [S
De minister] [V schoffeerde] [Adv gisteren] [O
zijn ambtenaten]
(25b). [Adv Gisteren] [V schoffeerde] [S de
minister] [O zijn ambtenaren]
(25c). [WH-O Wie] [V schoffeerde] [S de minister]
[Adv gisteren]?
(25d). [V Schoffeerde] [S de minister] [Adv
gisteren] [O zijn ambtenaren]?
(25e). (Een welingelichte bron verzekerde me) dat [S de minister]
[Adv gisteren] [O zijn ambtenaren] [V schoffeerde]
In de theoretische taalkunde hecht men groot belang aan analyses die zo simpel mogelijk zijn. Als we zoals in het geval van het Nederlands te maken hebben met verschillende woordvolgordes, zal men automatisch proberen uit te zoeken of die verschillende volgordes het resultaat zijn van dezelfde processen en of er sprake is van een onderliggende volgorde waaruit de verschillende volgordes die verschijnen in concrete taaluitingen voortkomen. De vraag is dan welke onderliggende volgorde we moeten aannemen voor het Nederlands. Onderzoek gedurende de afgelopen decennia heeft ertoe geleid dat men tegenwoordig algemeen een onderliggende SOV volgorde aanneemt voor het Nederlands (de volgorde in de bijzin in 25e). De SVO, VSO en OVS volgordes die op het nivo van PF verschijnen worden verklaard door aan te nemen dat de basis SOV volgorde gewijzigd wordt door verplaatsing van elementen. Hoe gaat dit precies in zijn werk?
Laten we eerst kijken naar de volgorde in de zinnen (25a-c). In de hoofdzinnen (25a) en (25b) mag dan sprake zijn van twee verschillende volgordes maar we kunnen wel de generalisatie maken dat in hoofdzinnen als (25a) en (25b) het geflecteerde werkwoord in tweede positie verschijnt. In (25a) is de eerste positie gevuld door het subject, terwijl in (25b) de eerste positie is gevuld met een adverbium ('gisteren'). Ook in vragende zinnen die beginnen met een vragend voornaamwoord (we noemen dit WH-questions) zoals (25c), en waar dus de eerste positie van de zin al gevuld is, komt het werkwoord in de tweede positie. Dit verschijnsel waarbij het geflecteerde of finiete werkwoord in hoofzinnen en WH-vraagzinnen in tweede positie geplaatst wordt, staat in de literatuur bekend als Verb-second.
Het zal duidelijk zijn dat, als we uitgaan van een onderliggende SOV-volgorde, er tijdens de afleiding van de zinnen (25a-c) één of meer verplaatsingen uitgevoerd moeten zijn. Natuurlijk kan een element alleen verplaatst worden van de ene naar de andere positie in de zin verplaatst worden als er een 'vrije' of 'lege' positie beschikbaar is voor het te verplaatsen element. Welke posities dat zijn wordt duidelijk als we kijken naar de structuur in (26) waarin we twee nog niet eerder genoemde non-lexical phrases, waarvan het hoofd dus niet V, N, A, of P is, tegenkomen: IP (Inflection Phrase) en CP (Complementizer Phrase). IP en CP hebben dezelfde gelaagde X-bar structuur als VP, NP, AP, en PP weergegeven in (21) en (22). IP en CP zijn de maximale projecties van niet-lexicale, zogenaamde functionele hoofden. Het hoofd van IP is de inflectie op het werkwoord, terwijl het hoofd van CP een zogenaamde complementizer is, een element dat een ondergeschikte complement-zin inleidt (Nederlandse complementizers zijn de voegwoorden 'dat', 'of', en betrekkelijke voornaamwoorden)
(26)
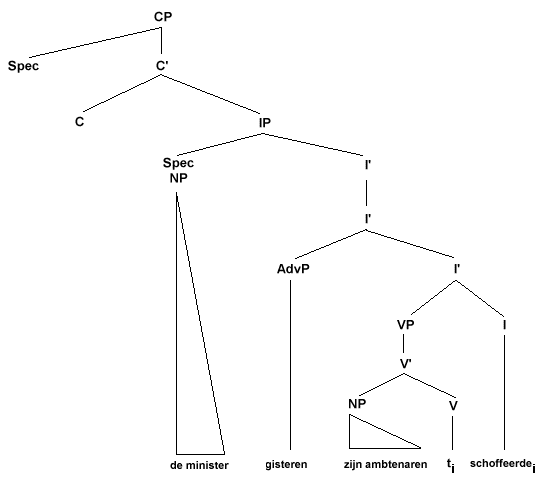
Je ziet dat de specifier-positie van IP ingenomen wordt door de NP die het subject van de zin is. De positie van de complementizer en de positie van de specifier van CP blijven echter leeg in de onderliggende structuur en bieden dus een zogenaamde landing site voor te verplaatsen elementen. Ik moet wel vermelden dat de structuur zoals hier weergegeven een aantal zaken onder de mat veegt waarover nogal wat discussie is. Het betreft vooral het nivo waarop de adverbiale consituent 'gisteren' is ingevoegd (je zou kunnen argumenteren dat deze een nivo lager onder VP thuishoort) en de plaats van het werkwoord 'schoffeer' ten opzichte van het flectiesuffix '-de'. Ik ga op deze problemen niet verder in (het laatste probleem wordt uitvoerig besproken, vooral aan de hand van Scandinavische talen, op Beatrice Santorini's web-presentatie bij haar syntaxis-college aan de University of Pennsylvania). Vrij algemeen wordt aangenomen dat 'schoffeer' (om redenen waar ik -alweer- niet verder op in zal gaan) een verplaatsing ondergaat van V naar I en daarmee 'versmelt'. Het finiete werkwoord 'schoffeerde' wordt dan in hoofzinnen van daaruit opnieuw verplaatst naar de complementizer-positie. Een verplaatst element laat een spoor of trace achter: dit wordt in haakjesnotatie en boomstructuren aangegeven door het spoor (of sporen bij opeenvolgende verplaatsingen) en het verplaatste element te co-indexeren met behulp van subscripten (hier: ti, waar t een afkorting is van 'trace').
Om de volgorde in (25a) te krijgen moeten er twee verplaatsingen plaatsvinden. De subject-NP 'de minister' wordt vanuit de specifier-positie van IP verplaatst naar de specifier-positie van CP en het finiete werkwoord 'schoffeerde' gaat van I naar C. Dit is weergegeven in (27).
(27)
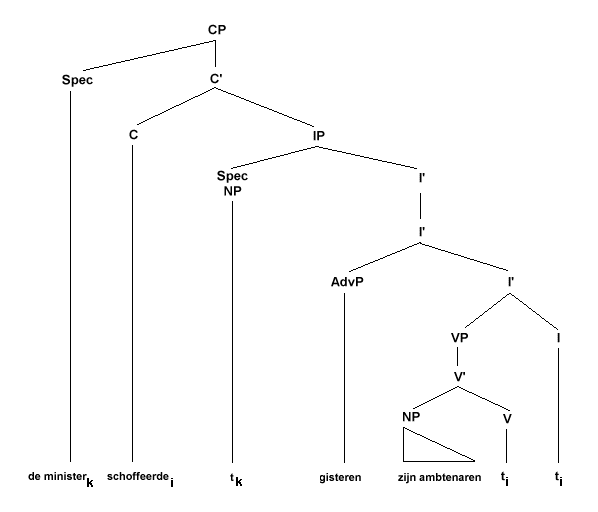
Om (25b) te krijgen zijn de volgende verplaatsingen nodig: het werkwoord gaat weer van I naar C en het bijwoord 'gisteren' gaat naar de specifier positie van CP:
(28)
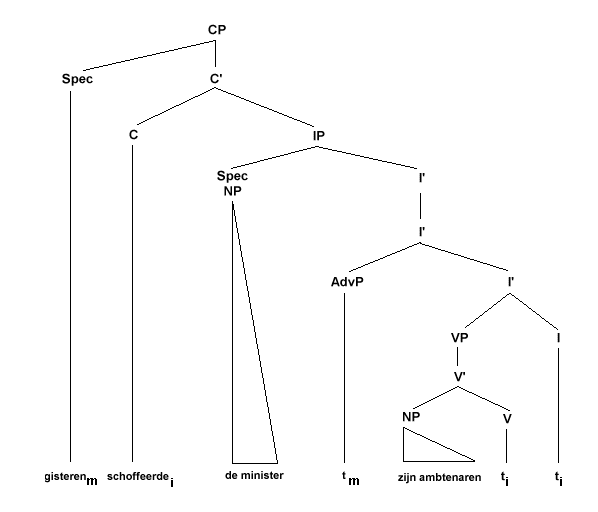
De volgorde in (25c) komt tot stand door het vragend voornaamwoord uit de Object-NP positie binnen VP te verplaatsen naar de Spec,CP positie:
(29)
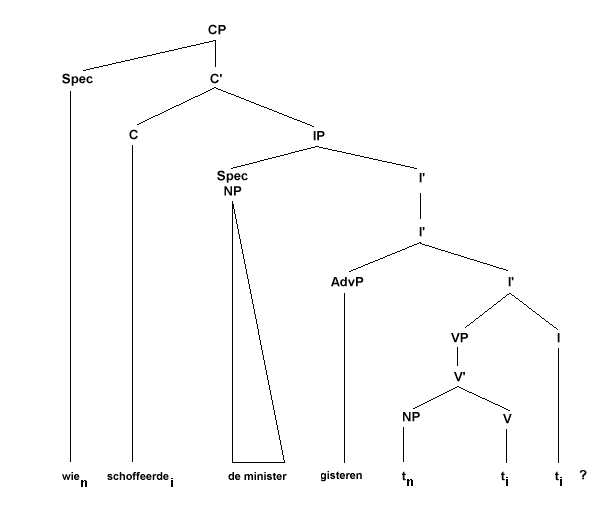
Om te volgorde van de ja/nee vraag in (25d) te krijgen is enkel verplaatsing van het werkwoord van I naar C nodig:
(30)
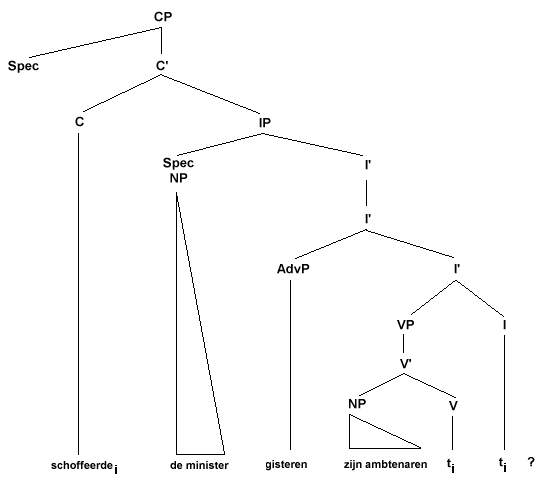
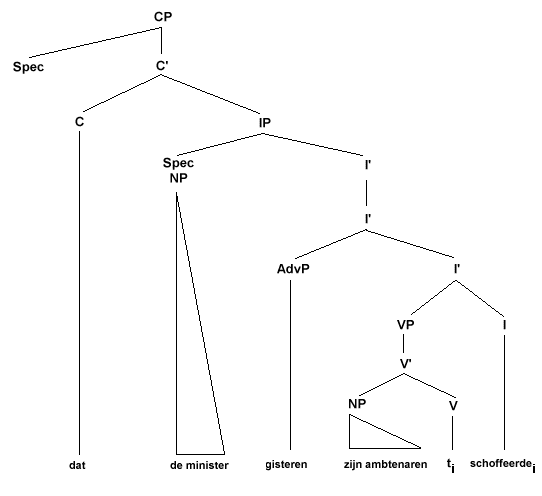
De S(Adv)OV bijwoordzinvolgorde uit (25e) tenslotte is die van de onderliggende structuur gegeven in (26), met dit verschil dat nu natuurlijk de complementizer-positie C gevuld is met de complementizer 'dat':
(31)
Op dit punt gekomen, vraag je je misschien af: "als ik elementen van een zin kan verplaatsen naar naar C en Spec,CP, kan ik dan niet ook een heleboel zinnen maken die absoluut ongrammaticaal zijn?" Het antwoord is 'nee', want verplaatsing is aan een scala van condities onderhevig die het aantal toegestane verplaatsingen sterk inperken. Als je hier meer over wilt weten, raadpleeg dan Haegeman (1991, of de herziene tweede editie uit 1994). Het sterke punt van het generatieve model weergegeven in (24) met zijn theoretische assumpties als verplaatsing en X-bar theory is dat variatie in PF verklaard kan worden door de interactie van een beperkt aantal principes. Je hebt dus een relatief simpel grammaticaal model van taal dat toch in staat is allerlei uiteenlopende verschijnselen te beschrijven en te verklaren.
In het voorgaande zijn de begrippen 'subject/onderwerp' en 'object/lijdend voorwerp' al enkele malen gevallen. Subject en object zijn syntactische begrippen en volledig te definiëren in termen van de formele relaties binnen de zin. Subject kunnen we definiëren als de NP die in de onderliggende zinsstructuur verschijnt in [Spec;IP] positie, terwijl object de NP is die fungeert als complement bij een transitief (of overgankelijk) werkwoord of bij een prepositie. Als we nu naar de volgende zinnen die hetzelfde proces beschrijven kijken, zien we dat de NP's waarvan de referent of entiteit constant blijft een andere syntactische rol toebedeeld krijgen.
(32a). [SubjectAgens
De burgemeester] overhandigde [ObjectPatiens de brandbrief] aan de
minister.
(32b). [SubjectPatiens De brandbrief] werd door [ObjectAgens
de burgemeester] aan de minister overhandigd
In beide zinnen is de entiteit die de actie van het overhandigen uitvoert 'de burgemeester' en de entiteit die deze actie ondergaat 'de brandbrief'. Beide entiteiten hebben in (32a) en (32b) dezelfde semantische rol: 'de burgemeester' heeft de rol van agens terwijl 'de brandbrief' de rol heeft van patiens. Toch zien we dat in de actieve zin (32a) de agens-NP als subject van de zin verschijnt terwijl in de passieve zin (32b) dezelfde agens-NP als object-complement van een PP wordt opgevoerd. Dit maakt duidelijk dat de syntaxis de mogelijkheid biedt om dezelfde actie of proces op verschillende manieren te coderen. Het passief maken van een zin zoals hier maakt het bijvoorbeeld mogelijk om van een patiens-NP een referentiële uitdrukking te maken die door een predicerende uitdrukking nader wordt gespecificeerd. Met andere woorden: in passieve zinnen neemt de patiens-NP de prominente subject-rol in die een agens-NP heeft in actieve zinnen. De agens-NP in passieve zinnen krijgt een meer perifere status in de informatiestructuur van de zin als deel van een 'door'-bepaling of kan zelfs helemaal weggelaten worden (en dat kan handig zijn als je de agens niet wilt noemen of als je de agens niet kent).
Welke thematische rollen moeten worden toegekend in een zin is afhankelijk van het werkwoord in die zin. Ieder werkwoord behoort tot een bepaalde subcategorie werkwoorden met een eigen rollenspecificatie. Zo zijn er werkwoorden die enkel een agens-rol eisen, zoals 'springen'. Dit soort werkwoorden wordt traditioneeel aangeduid als intransitief of onovergankelijk. Andere werkwoorden, zoals 'slaan', eisen een agens - en een patiens-rol en worden transitieve werkwoorden genoemd. Werkwoorden uit weer een andere categorie eisen een agens, patiens, en een recipiens of benefactief. Een voorbeeld van zo'n werkwoord is 'geven'. In de zinnen (33)-(35) wordt getoond door welke syntactische rollen semantische rollen bij deze werkwoorden uitgedrukt kunnen worden. In (33) zien we een agens ('de jongen') uitgedrukt als een subject en, als optioneel argument, de cause 'blijdschap' dat uitgedrukt wordt als een object-complement bij een prepositie ('van'). In (34) zien we een subject-agens ('het schoolhoofd'), een object-patiens ('de leerling'), en een object-instument, waarbij het object als complement fungeert bij de prepositie 'met'. In (35) zien we een voorbeeld van een recipiens ('de junkie') uitgedrukt als (indirect) object. In (36a-b) zien we dat het benoemen van semantische rollen niet altijd even makkelijk is. Soms is het mogelijk de actie of toestand die door het werkwoord wordt beschreven te zien vanuit meerdere perspectieven. Als we de actie vanuit het perspectief van de junkie bekijken is er sprake van een pakje dat hij ontvangt door toedoen van de dealer. Zo is 'de junkie' recipiens, 'het pakje bruin' patiens, en 'de dealer' agens. Je kunt echter ook een meer afstandelijk perspectief hanteren en het beschreven proces zien als de verplaatsing van een entiteit ('het pakje bruin') van een bepaalde plaats ('de dealer') naar een andere ('de junkie'). In dat geval is 'de junkie' goal (bestemming), 'het pakje bruin' theme (het argument dat een verandering van plaats ondergaat), en 'de dealer' source ('oorsprong').
(33). [SubjectAgens
De jongen] sprong van [ObjectCause blijdschap]
(34). [SubjectAgens Het schoolhoofd] sloeg [ObjectPatiens
de leerling] met [ObjectInstrument een rietje]
(35). [SubjectAgens De dealer] gaf [ObjectRecipiens de
junkie] [ObjectPatiens een pakje bruin]
(36a). [SubjectRecipiens De junkie] kreeg [ObjectPatiens
een pakje bruin] van [ObjectAgens de dealer].
(36b). [SubjectGoal De junkie] kreeg [ObjectTheme een
pakje bruin] van [ObjectSource de dealer].
Je ziet dat ook andere semantische rollen dan agens, patiens, en recipiens bestaan. Deze zijn vaak optioneel en niet verplicht: het zijn dan zogenaamde perifere argumenten bij het werkwoord. Afhankelijk van theoretische oriëntatie, onderscheiden taalkundigen ongeveer 10 tot 15 verschillende semantische rollen. In het Nederlands gebruiken we meestal de Latijnse of Engelse benaming voor semantische rollen. De semantische rollen die een werkwoord toekent bepalen de valentie van dat werkwoord. Soms wordt de configuratie van semantische rollen bij een bepaald werkwoord ook wel het predikaatschema genoemd. In de Chomskyaanse taalkunde worden semantische rollen thematische of theta-rollen genoemd.
Deze korte sectie over syntactische en semantische rollen laat zien dat er een belangrijke interface is tussen syntaxis en mentale lexicon waar individuele lexicale items of lexemen liggen opgeslagen. Elk werkwoordlexeem bevat informatie over verplichte en optionele argumenten bij dat werkwoord. Het is deze informatie over semantische rollen die in syntactische operaties een cruciale rol speelt bij de totstandkoming van zinsstructuur.
In tegenstelling tot fonemen, hebben (vrije) morfemen, constituenten, en uitingen, het terrein van morfologie en syntaxis, wel degelijk betekenis. Kun je fonologische systemen nog bestuderen als volledig losstaand van het sociaal-culturele universum waarin ze gebruikt worden, de studie van morfologie en syntaxis dwingt de onderzoeker te kijken naar de relatie tussen de vorm van de geobserveerde taaluitingen en hun inhoud. In de volgende colleges komt die relatie vorm-inhoud uitvoerig aan bod. Niet alleen gaan we kijken naar hoe variatie in vorm correspondeert met variatie in talige informatie maar ook hoe variatie in vorm samenhangt met het uitdrukken van specifieke sociale en culturele informatie of betekenis.
Spencer (1991) is een uitstekende uitgebreide (en ook pittige) inleiding die weinig voorkennis vereist; het accent ligt op ontwikkelingen in de generatieve taalkunde
Spencer & Zwicky, eds. (1998) is een lijvig handboek met bijdragen van vele specialisten voor diegenen die echt de diepte in willen duiken
Booij & van Zanten (1998) is een goede inleiding tot de morfologie aan de hand van het Nederlands
Binnen de taalkunde bestaan een heleboel verschillende theoretische benaderingen die zich bezighouden met syntaxis. De Chomskyaanse, generatieve traditie is veruit de meest toonaangevende, maar ook functionele en cognitieve benaderingen zijn belangrijk. De meeste literatuur op het gebied van de syntaxis die het niveau voor beginnelingen ontstijgt is direct al behoorlijk pittig om te lezen en te verwerken. Daarbij is alles wat in druk verschijnt eigenlijk al verouderd op het moment dat je het leest. Juist omdat ontwikkelingen, met name in de Chomskyaanse taalkunde, erg snel gaan, is het een goed idee om websites bij syntaxis colleges te bezoeken. Een hele goede is de al genoemde site van Beatrice Santorini.
Droste & Joseph (1991): handig overzicht van de meest vooraanstaande syntactische theorieën
Givón (1984,1990): als je ook eens een andere dan een Chomskyaanse visie op syntaxis wilt, is dit werk erg verfrissend; erg veel aandacht voor hoe de vorm van zinnen samenhangt met de functie(s) ervan
Shopen, ed. (1985a,b): twee erg goede verzamelingen van artikelen die geen al te grote voorkennis vereisen; je krijgt door het lezen van deze artikelen een goede indruk van de verschillen en overeenkomsten tussen de talen van de wereld; veel aandacht ook voor Niet-Westerse talen
Verwijzingen
Appel, René, et al. (1992). Inleiding tot de algemene taalwetenschap. Dordrecht: ICG Publications.
Booij, Geert, en Ariane van Santen. (1998). Morfologie: De woordstructuur van het Nederlands. Amsterdam: Amsterdam University Press.
Droste, Flip G. and John E. Joseph. (1991). Linguistic Theory and Grammatical Description. Amsterdam: John Benjamins.
Givón, T. (1984). Syntax: A functional-typological introduction (Vol.I). Amsterdam: John Benjamins.
Givón, T. (1990). Syntax: A functional-typological introduction (Vol.II). Amsterdam: John Benjamins.
Haegeman, Liliane. (1991). Introduction to government & binding theory. Oxford: Blackwell.
Haegeman, Liliane. (1994). Introduction to government & binding theory (Second Edition). Oxford: Blackwell.
Kerke, Simon van de. (1996). Affix order and interpretation in Bolivian Quechua. (PhD. Dissertation, University of Amsterdam)
Shopen, Timothy (ed.). (1985a). Language typology and syntactic description. Volume I: Clause structure. Cambridge: Cambridge University Press.
Shopen, Timothy (ed.). (1985b). Language typology and syntactic description. Volume II: Complex constructions. Cambridge: Cambridge University Press.
Spencer, Andrew. (1991). Morphological theory: an introduction to word structure in generative grammar. Oxford: Blackwell.
Spencer, Andrew, and Arnold Zwicky (eds.). (1998). The handbook of morphology. Oxford: Blackwell.
Veenstra, Tonjes. (1996). Serial verbs in saramaccan: Predication and creole genesis. Den Haag: Holland Academic Graphics. (PhD Dissertation, University of Amsterdam)
![]() terug
naar het begin van deze pagina
terug
naar het begin van deze pagina
![]() terug
naar de Taal & Communicatie home page
terug
naar de Taal & Communicatie home page
All text and images on these pages (citations and images from other sources
excepted)
© Vincent A. de Rooij
first published: 31 January 2000
last revised & updated: 25 January 2001